MatPL 可用参数
本节介绍了所有模型中可由用户定义的参数,可以分为基础参数和高级参数两类。基础参数需要用户指定,高级参数采用了默认值,用户可以在 json 文件中根据需求手动修改。在下面的参数中,"相对路径(relative path)" 表示相对于当前工作目录的路径,而 "绝对路径(absolute path)" 表示从根目录开始的文件或目录的完整路径。
基础参数
model_type
该参数用于指定用于训练的模型类型。您可以使用LINEAR模型、NN模型、DP模型或 NEP 模型。
atom_type
该参数用于设置训练体系的元素类型。用户可以按��照任意顺序指定元素的原子序数。例如,对于单元素系统如铜,可以设置为 [29],而对于多元素系统如 CH4,则可以设置为 [1, 6]。您也可以使用元素类型的名称,例如["Cu"] 或者 ["H", "C"]。
train_data
该参数用于指定训练集数据路径。您可以使用相对路径或绝对路径。
- 对于 DP 和 NEP 模型,支持的文件格式有
extxyz、pwmlff/npy、deepmd/npy、deepmd/raw、pwmat/movement,vasp/outcar,cp2k/md - 对于 LINEAR 和 NN 模型,仅支持
pwmat/movement格式
valid_data
该参数用于指定验证集数据路径。您可以使用相对路径或绝对路径。
- 对于 DP 和 NEP 模型,支持的文件格式有
extxyz、pwmlff/npy、deepmd/npy、deepmd/raw、pwmat/movement,vasp/outcar,cp2k/md - 对于 LINEAR 和 NN 模型,仅支持
pwmat/movement格式
test_data
该参数用于test命令做推理时指定测试集数据路径。您可以使用相对路径或绝对路径。
- 对于 DP 和 NEP 模型,支持的文件格式有
extxyz、pwmlff/npy、deepmd/npy、deepmd/raw、pwmat/movement,vasp/outcar,cp2k/md - 对于 LINEAR 和 NN 模型,仅支持
pwmat/movement格式
format
该参数用于指定数据(train_data、valid_data、test_data)的格式,支持的数据格式有扩展的xyz格式 extxyz 、pwmlff/npy、deepmd/npy、deepmd/raw格式。此外也支持直接使用 PWmat, VASP, CP2K 轨迹文件, 对应 format 参数分别为 pwmat/movement, vasp/outcar, cp2k/md。默认格式为 pwmat/movement。细节请参考数据格式转换工具pwdata。
注意,输入数据的格式需要一致。
model_load_file
- 该参数一般用于微调或者和继续训练时,指定初始待训模型路径,支持文件格式为后缀为
.ckpt的模型文件。 - 该参数用于
test命令做推理时指定模型的路径,支持相对或者绝对路径。
nep_txt_file
- 该参数一般用于微调或者和继续训练时,指定初始待训模型路径,支持文件格式为后缀为
.txt的模型文件。力场文件可以是来自 GPUMD 的 nep4.txt 或 nep5.txt。 - 这里的 txt 文件也可以是通用力场文件(89种元素类型)。在解析时会从中提取出在
atom_type中指定的元素类型对应的参数,该功能一般用于从通用力场模型微调出小模型。此时,可以与model->fitting_net中的fix_cij、fix_hiddenlayer、fix_outlayer配合使用。
recover_train
该参数用于从中断的训练任务中恢复训练。默认值为 true
reserve_work_dir
该参数用于LINEAR 或者 NN 模型,用于指定在任务执行完成后是否保留工作目录 work_dir。默认值为 False,意味着在执行完成后该目录将被删除。
save_step
该参数用于设置每隔多少个iteration保存一次模型,默认值为 None,即只在每个epoch训练结束后保存一次模型。
max_save_num
该参数用与 save_step 配合使用,用于设置最多保存 max_save_num 个最近的模型。默认值为 10, 仅在设置 save_step 后起作用。
NEP 模型超参数
完整的 NEP 模型参数设置如下:
"batch_max_types":-1,
"model": {
"descriptor": {
"cutoff": [6.0,6.0],
"n_max": [4,4],
"basis_size": [12,12],
"l_max": [4,2,1],
"zbl": 2.0
},
"fitting_net": {
"network_size": 40,
"fix_cij":false,
"fix_hiddenlayer":false,
"fix_outlayer":false
}
}
batch_max_types
该参数用于设置batch内允许的最大元素数量,超过该数量的结构在本次训练中会被丢弃。一般用于大batchsize下训练通用力场(如89种元素的训练数据集),防止个别数据由于元素类型较多或近邻数量过大造成的显存溢出错误。默认不设置,即不控制。
cutoff
该参数用于设置 radial 和 angular 的截断能。默认值为 [8.0, 4.0]。
n_max
该参数用于设置 radial 和 angular分别对应的描述符数量,该值不小于0,不大于 19,默认值为 [4, 4]。
basis_size
该参数用于设置 radial 和 angular对应的基组数量,该值不小于0,不大于 19默认值为 [8, 8]。
l_max
该参数用于设置 angular 的展开阶,同时控制是否使用四体和五体描述符,默认值为 [4, 2, 1],分别是三体、四体以及五体 描述符 对应的阶。这里 2表示使用四体 描述符,1 表示使用五体描述符。如果您只使用三体描述符,请设置为[4, 0, 0];只是用三体和四体描述符,请设置为[4, 2, 0]。
NEP 两体描述符的数量为 n_max[0]+1;三体描述符的数量为 (n_max[1] + 1)*l_max[0],四体描述符、五体描述符数量相同,分别为 n_max[1] + 1。
network_size
该参数用于设置 NEP 模型中隐藏层神经元个数,在 NEP 模型中只有一层隐藏层,默认值为 40。
zbl
该参数用于设置Ziegler-Biersack-Littmark (ZBL) 势,处理原子距离非常近的情况。默认不设置。该值的允许范围是 1.0 zbl 2.5。
fix_cij
该参数用于在训练中固定 NEP 两体和三体特征值对应的系数项,默认为false。设置为true之后�,训练过程中将不再训练更新系数项。
fix_hiddenlayer
该参数用于在训练中固定 NEP 隐藏层参数,默认为false。设置为true之后,训练过程中将不再训练更新隐藏层参数。这里 NEP 的隐藏层指输入层的W0、B0项。
fix_outlayer
该参数用于在训练中固定 NEP 输出层参数,默认为false。设置为true之后,训练过程中将不再训练更新输出层参数。这里 NEP 的输出层指W1、B1项。
NEP.txt 中的每行参数解读
NEP.txt的文件头内容解析,如下是一个标准的NEP.txt文件头部内容。
nep5 2 O Hf # 2 元素类型数量,后跟元素类型
zbl 1 2 # 训练开启 zbl 之后存在本行,否则不存在
cutoff 6.0 6.0 108 108 # 两体cutoff 多体cutoff 两体最大近邻数量 多体最大近邻数量
n_max 4 4 # 两体 n_max 参数 多体n_max参数
basis_size 12 12 # 两体 basis_size 参数, 多体 basis_size 参数
l_max 4 2 1 # l_max 参数: 4为三体值,2为四体值,1为五体值
ANN 40 0 # 40 为隐藏层个数 0没有具体意义,只占位
接下来的行可以按照顺序分为网络参数、两体特征系数、三体特征系数、归一化值四个块。
-
第一块数据网络参数。网络数量数量(Ei = tanh([qn*W0]+B0)*W1 + b1) = 原子类型数量 * (特征数量 * ANN[0] + ANN[0] + ANN[0]) + 原子类型数量。按照第一行的元素类型顺序,分别是对应元素的W0、B0、W1;接下来是每个元素类型对应 b1(单值)。如果是 gpumd 训练的力场,对应nep4,这里的b1 只有1个值,是所有原子类型的b1的均值。对于W0,每行的顺序对应维度为 [隐�藏层ANN,特征值数量] 按照行存储的顺序。
-
第二块两体系数。数量 = 元素数量的平方 * (n_max[0]+1) * (basis_size[0]+1)
-
第三块三体系数。数量 = 元素数量的平方 * (n_max[1]+1) * (basis_size[1]+1)
对于两体或者三体块内的每个参数顺序:系数矩阵为[I, J, N, K],I为中心原子类型,J为近邻原子类型,顺序与第一行中的元素类型顺序一致,N为n_max+1,K为basis_size+1
-
第四块归一化值。数量与特征值数量相同,顺序分别为两体、三体、四体、五体。这里特征值数量=两体+三体+四体+五体特征数量:两体项数量 = n_max[0] + 1,三体项数量 = (n_max[1] + 1) * l_max[0],四体项数量 = n_max[1] + 1,五体项数量 = n_max[1] + 1
DP 模型超参数
DP 模型的完整参数设置如下:
"type_embedding":false,
"model": {
"type_embedding":{
"physical_property":["atomic_number", "atom_mass", "atom_radius", "molar_vol", "melting_point", "boiling_point", "electron_affin", "pauling"]
},
"descriptor": {
"Rmax": 6.0,
"Rmin": 0.5,
"M2": 16,
"network_size": [25,25,25]
},
"fitting_net": {
"network_size": [50,50,50,1]
}
}
type_embedding
该参数用于 DP 模型训练开启type embedding时设置相应参数。您也可以在'model'同级字典下设置"type_embedding":true,此时将采用 ["atomic_number", "atom_radius", "atom_mass", "electron_affin", "pauling"]设置。默认值为false,不开启type_embdding。
physical_property
该参数用于指定 DP 模型在做 type embedding 方式训练时需要的参数,我们这里提供了 8 个物理属性供用户选择。
- atomic_number: 原子序数
- atom_mass: 原子质量
- atom_radius: 原子半径
- molar_vol: 摩尔体积
- melting_point: 熔点
- boiling_point: 沸点
- electron_affin: 电子亲和能
- pauling 为泡林电负性
"physical_property" 默认值为 ["atomic_number", "atom_radius", "atom_mass", "electron_affin", "pauling"]
Rmax
DP 模型中平滑函数的最大截断半径。默认值为 。
Rmin
DP 模型中平滑函数的最小截断半径。默认值为 。
M2
该参数用于 DP 模型中的网络,确定嵌入网络的输出大小和拟合网络的输入大小。在示例中,嵌入网络的输出大小为(25 X 16),拟合网络的输入��大小为(25 X 16 = 400)。默认值为 16。
network_size
该参数用于嵌入网络(embedding_net)和拟合网络(fitting_net)的结构。默认值分别为[25, 25, 25]和[50, 50, 50, 1]。对应的网络结构如下所示:
嵌入网络的结构: 输入层(输入数据维度)-> 隐藏层 1(25 个神经元)-> 隐藏层 2(25 个神经元)-> 输出层 3(25 个神经元)
拟合网络的结构: 输入层(M2 X 25)-> 隐藏层 1(50 个神经元)-> 隐藏层 2(50 个神经元)-> 隐藏层 3(50 个神经元)-> 输出层(1 个神经元)
NN 模型超参数
NN 模型的完整参数设置如下:
"model": {
"descriptor": {
"Rmax": 6.0,
"Rmin": 0.5,
"feature_type": [3,4]
},
"fitting_net": {
"network_size": [15,15,1]
}
}
Rmax
特征的最大截断半径。默认值为 。
Rmin
特征的最小截断半径。默认值为 。
feature_type
该参数用于特征类型。支持的选项有[1, 2]、[3, 4]、[5]、[6]、[7]和[8]。默认值为[3, 4],即 2-b 和 3-b 高斯特征。有关不同特征类型的更详细信息,请参考附录1。
network_size
该参数用于拟合网络(fitting_net)的结构。默认值为[15, 15, 1],其结构如下所示: 输入层(输入数据维度)-> 隐藏层 1(15 个神经元)-> 隐藏层 2(15 个神经元)-> 输出层(1 个神经元)
Linear 模型超参数
Linear 模型的完整参数设置如下:
"model": {
"descriptor": {
"Rmax": 6.0,
"Rmin": 0.5,
"feature_type": [3,4]
}
}
Rmax
特征的最大截断半径。默认值为 。
Rmin
特征的最小截断半径。默认值为 。
feature_type
该参数用于特征类型,与NN 模型中的设置相同。支持的选项有[1, 2]、[3, 4]、[5]、[6]、[7]和[8]。默认值为[3, 4],即 2-b 和 3-b 高斯特征。有关不同特征类型的更详细信息,请参考附录1。
ADAM optimizer 优化器超参数
ADAM 优化器的完整参数设置如下:
"optimizer": {
"optimizer": "ADAM",
"epochs": 30,
"batch_size": 1,
"print_freq": 10,
"lambda_2" : 0.1,
"learning_rate": 0.001,
"stop_lr": 3.51e-08,
"stop_step": 1000000,
"decay_step": 5000,
"train_energy": true,
"train_force": true,
"train_virial": false,
"start_pre_fac_force": 1000,
"start_pre_fac_etot": 0.02,
"start_pre_fac_virial": 50.0,
"end_pre_fac_force": 1.0,
"end_pre_fac_etot": 1.0,
"end_pre_fac_virial": 1.0
}
optimizer
该参数用于指定优化器名称,默认为ADAM。对 LKF 优化器,指定名称为 'LKF'。关于优化器的详细信息参考 LKF,其中提供了有关优化器实现和特性的更深入的细节说明。
epochs
该参数用于指定训练的轮数(epochs)。在机器学习中,一个 epoch 指的是整个训练数据集通过神经网络的完整传递,包括前向传播和反向传播。在每个 epoch 中,训练数据集分为多个 小批量(mini-batches) 样本,之后把每个批次输入到神经网络,进行前向传播、损失计算和参数更新的反向传播过程。训练的轮数决定了整个训练数据集在训练过程中被处理的次数。默认值为 30。
通常需要通过调试和评估训练过程来选择适当的训练轮数。如果训练轮数过小,模型可能无法充分学习数据集的模式和特征,导致欠拟合。另一方面,如果训练轮数过大,模型可能会过拟合训练数据,在新数据上的泛化性能下降。
batch_size
批大小(batch size)参数确定了在每个 epoch 的训练过程中,每个小批量(mini-batch)中包含的训练样本数量。默认值为 1。
print_freq
该参数用于指定每经过多少个小批量迭代之后打印一次训练误差。默认值为 10。
train_energy
该参数用于指定是否训练 total energy,默认值为 true。
train_force
该参数用于指定是否训练 force,默认值为 true。
train_virial
该参数用于指定是否训练 virial,默认值为 false。
lambda_2
该参数用于设置 Adam 优化器的 L2 正则化项,默认不设置。设置正则化项有助于减少模型的过拟合。
learning_rate
该参数是 Adam 优化器的初始学习率。默认值为 0.001。
stop_lr
该参数是指停止学习率,表示当学习率降到该值时学习率将停止更新,后续训练学习率为该值。默认值为 3.51e-08。
stop_step
该参数是指停止步数(stopping step),表示当达到该步数时学习率将停止更新,此时学习率值等于 stop_lr 指定的值。stop_step 默认值为 1000000。
decay_step
该参数表示衰减步数(decay step),它指定了学习率衰减的间隔。在每个衰减步数之后,学习率会根据一定的衰减率进行更新。默认值为 5000。
learning_rate, stop_lr, stop_step, decay_step 这四个变量用于更新学习率,其计算过程如下所示,可以使用以下的 Python 代码或数学公式表示:
decay_rate = np.exp(np.log(stop_lr/learning_rate) / (stop_step/decay_step))
real_lr = learning_rate * np.power(decay_rate, (iter_num//decay_step))
首先计算衰减率(decay_rate):
更新学习率 learning rate:
其中,iter_num 代表训练过程中的迭代次数。
start_pre_fac_force
训练开始时 force 损失的 prefactor,应大于或等于 0。默认值为 1000。
start_pre_fac_etot
训练开始时 total energy 损失的 prefactor,应大于或等于 0。默认值为 0.02。
start_pre_fac_virial
训练开始时 virial 损失的 prefactor,应大于或等于 0。默认值为 50.0。
!-- #### start_pre_fac_egroup
训练开始时 egroup 损失的 prefactor,应大于或等于 0。默认值为 0.02。
end_pre_fac_force
训练结束时 force 损失的 prefactor,应大于或等于 0。默认值为 1.0。
end_pre_fac_etot
训练结束时 total energy 损失的 prefactor,应大于或等于 0。默认值为 1.0。
end_pre_fac_virial
训练结束时 virial 损失的 prefactor,应大于或等于 0。默认值为 1.0。
max_norm & norm_type (按范数裁剪)
参数 max_norm 和 norm_type 配合使用,用于设置按照范数裁剪梯度。max_norm 默认值为 None,不使用按范数裁剪。
计算所有参数梯度的范数,如果超过max_norm (max_norm 为 浮点值),则按比例缩放梯度使范数等于max_norm。
作用:保持梯度方向的相对关系(所有梯度同比例缩放);适合防止梯度爆炸的同时保留梯度间的平衡;norm_type可选(如L2范数、L1范数等)。
norm_type,整形值,取值为 1或 2,1 表示用 L1 范数,2 表示用 L2 范数。默认值为2,启用了按范数裁剪时,将默认按L2范数裁剪。
L1 范数是梯度的绝对值之和: , 如果 ,则梯度会被缩放为:
L2 范数是梯度的欧几里得范数: , 如果 ,则梯度会被缩放为:
clip_value (按值裁剪)
按值裁剪梯度。直接将所有梯度元素裁剪到[-clip_value, clip_value]区间,超过阈值的梯度被截断。默认值为 None, 不使用按值裁剪。
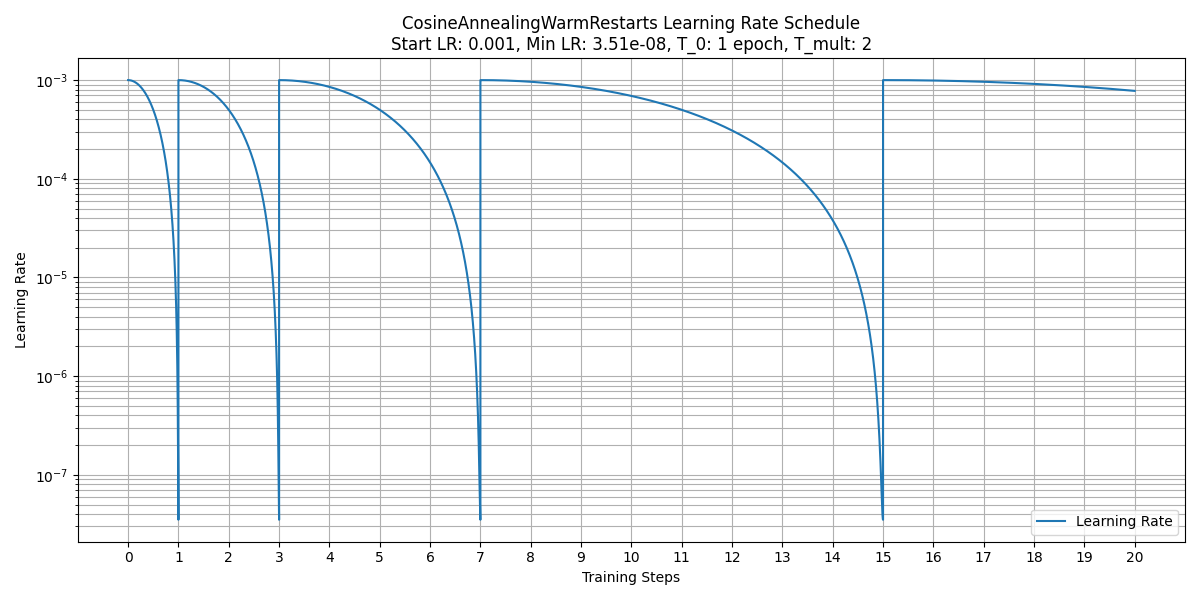
t_0 & t_mult
参数 t_0 和 t_mult 配合使用,用于设置在 ADAM 优化器中使用余弦退火算法更新学习率。注意:启用了余弦退火后,学习率的更新由调度器 optim.lr_scheduler.CosineAnnealingWarmRestarts 完全接管,在decay_step中的学习率更新策略将失效。
- T_0 学习率第一次回到初始值的epoch位置;
- T_mult 控制学习率变化的速度。如果T_mult=1,则学习率在T_0,2T_0,3T_0,....,i*T_0,....处回到最大值(初始学习率);如果T_mult>1,则学习率在T_0,(1+T_mult)*T_0,(1+T_mult+T_mult**2)*T_0,.....,(1+T_mult+T_mult2+...+T_0i)*T0,处回到最大值。如果开启余弦退火策略,在训练过程中,每次重启学习率前(即学习率最低点)的模型将保存在
model_record/saved_models目录下。
如下图所示,该例中初始学习率 learning_rate 为 0.001,T_0 = 1, T_mult = 2, 最小学习率 stop_lr = 3.51e-08。
KF optimizer 优化器超参数
KF 优化器的完整参数设置如下:
"optimizer": {
"optimizer": "LKF",
"epochs": 30,
"batch_size": 1,
"print_freq": 10,
"block_size": 5120,
"p0_weight": 0.01,
"kalman_lambda": 0.98,
"kalman_nue": 0.9987,
"train_energy": true,
"train_force": true,
"train_virial": false,
"pre_fac_force": 2.0,
"pre_fac_etot": 1.0,
"pre_fac_virial": 1.0
}
optimizer, epochs, batch_size, print_freq, train_energy, train_force, train_virial 参数与 ADAM 优化器中的参数功能相同。
block_size
该参数是LKF 优化器的超参数,用于指定协方差矩阵 P 的块大小。较大的块大小会增加内存和 GPU 内存的消耗,导致训练速度较慢,而较小的块大小会影��响收敛速度和准确性。默认值为 5120,如果是在 A100、H100 等高端显卡上,建议设置为 10240。
p0_weight
该参数是 LKF的超参数,用于正则化参数,默认值为0.01,即采用正则化。设置正则化项有助于减少模型的过拟合。该参数要求值小于 1 ,经过测试 0.01 是较为合适的值。如果设置为 1 则表示不使用正则化。
kalman_lambda
该参数是LKF的超参数,称为记忆因子(memory factor)。它决定了对先前数据的权重或关注程度。值越大,越重视先前的数据。默认值为 0.98。
kalman_nue
该参数是LKF的超参数,kalman_nue 是遗忘率(forgetting rate),描述了 kalman_lambda 变化的速率。默认值为 0.9987。
pre_fac_etot
该参数用于指定 total energy 对损失函数的权重或贡献。默认值为 1.0。
pre_fac_force
该参数用于指定 force 对损失函数的权重或贡献。默认值为 2.0。
pre_fac_virial
该参数用于指定 virial 对损失函数的权重或贡献。默认值为 1.0。
-
NEP的多卡训练不支持 LKF 或 GKF 优化器。
-
由于 KF 优化器中的 P矩阵规模是训练参数量 N/block_size 的平方,因此当训练元素类型较多时,容易出现显存爆炸以及收敛缓慢的情况。