NEP
操作演示
模型介绍
NEP模型最初是在 GPUMD 软件包中实现的 (2022b GPUMD)。GPUMD 中训练 NEP 采用了可分离自然演化策略(separable natural evolution strategy,SNES),由于不依赖梯度信息,实现简单。但是对于标准的监督学习任务,特别是深度学习,更适合采用基于梯度的优化算法。我们在 MatPL 2025.3 版本实现了 NEP 模型(NEP5,网络结构如图1所示),能够使用 MatPL 中基于梯度的 LKF 或 ADAM 优化器做模型训练。并且我们对梯度计算中的耗时部分通过 c++ cuda 算子做了优化,大幅提升了训练速度。
我们在多种体系中比较了LKF 和 SNES 两种优化方法的训练效率,测试结果表明,LKF 优化器在对NEP模型的训练中展现了优越的训练精度和收敛速度 NEP模型的网络结构只有一个单隐藏层,具有非常快的推理速度,而引入LKF优化器则大幅提高了训练效率。用户可以在 MatPL 中以较低的训练代价获得优质的NEP并使用它进行高效的机器学习分子动力学模拟,这对于资源/预算有限的用户非常友好。
我们也实现了 NEP 模型的Lammps分子动力学接口,支持 CPU 或 GPU 设备,受益于NEP 简单的网络结构和化繁为简的feature设计,NEP 模型在 lammps 推理中具有非常快的速度,并支持跨节点(跨节点 GPU)。
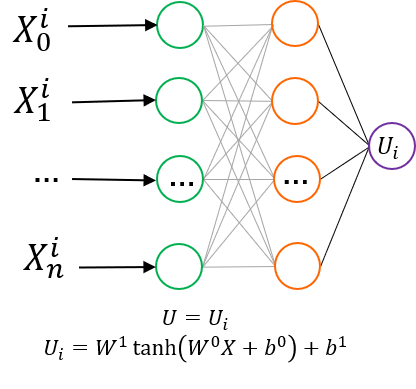
NEP 网络结构,不同类型的元素具有独立但结构相同的子神经网络。此外,与文献中 NEP4 网络结构不同的是,对于每层的bias,所有的 子网络不共享最后一层bias,在GPUMD 中为 NEP5。
lammps 接口测试
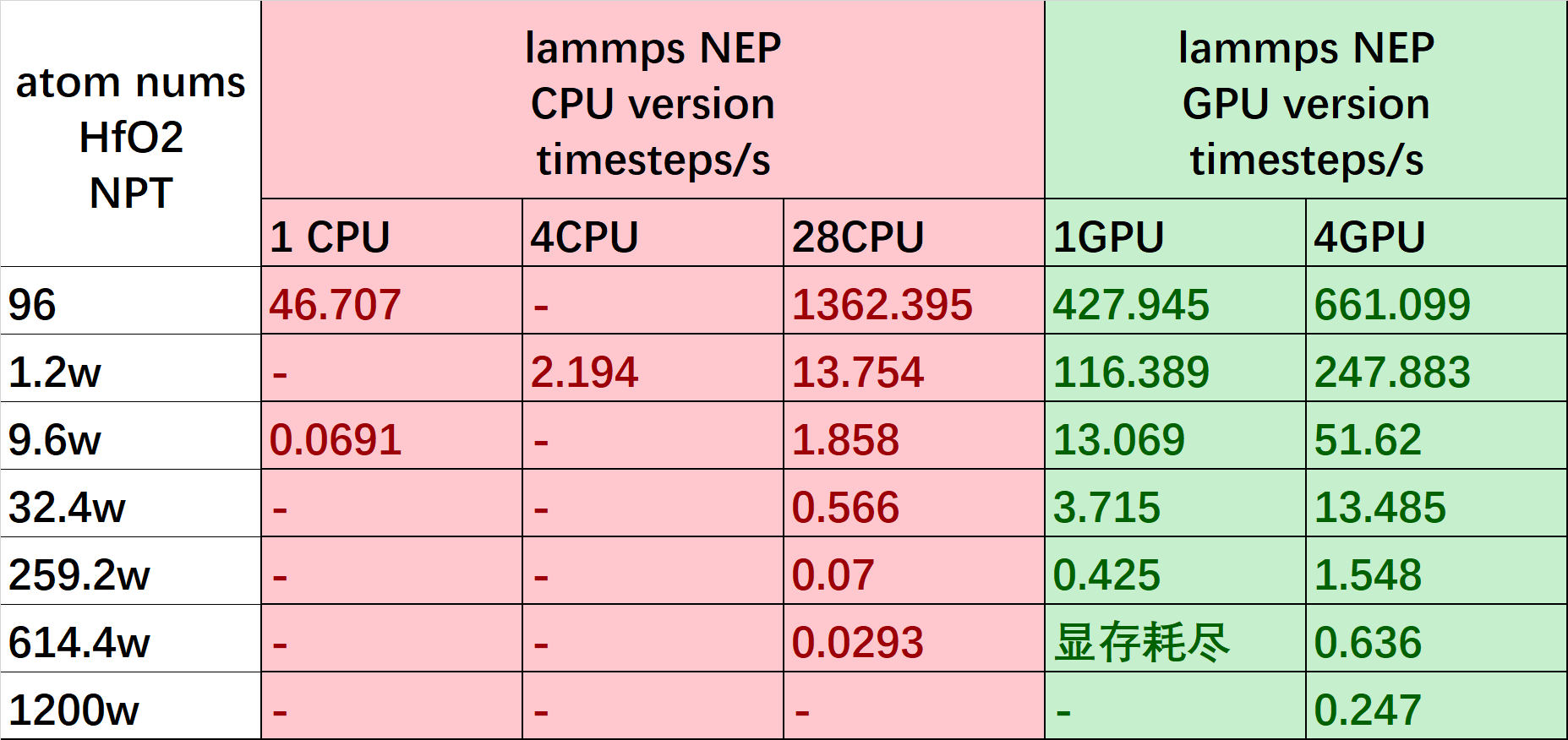
下图展示了 NEP 模型的 lammps CPU 和 GPU 接口在 3090*4 机器上做 NPT 系综 MD 模拟的速度。对于CPU 接口,速度正比与原子规模和CPU核数;对于GPU 接口, 速度正比与原子规模和GPU数量。
根据测试结果,我们建议如果您需要模拟的体系规模在 量级以下,建议您使用 CPU 接口即可。另外使用 GPU 接口时,建议您使用的 CPU 核数与 GPU 卡数相同。